はじめに
前回請求書モデルを使ってAI-OCRのできるWebAPIをさくっと作りました。
usomarutech.com
そのときのデータ加工をしていたコードの中身と特有のクラスについてまとめます。
ソースコード
public async Task<AnalyzeData> GetAnalysisOfInvoiceData(IFormFile invoiceFile) { var analyzeResult = await _formRecognizerRepository.GetInvoiceData(invoiceFile); if (analyzeResult != null) { AnalyzedDocument document = analyzeResult.Documents[0]; var documentList = document.Fields.ToList(); return FormatAnalysis(documentList); } return new AnalyzeData(); }
こちらはコードの3行目でDocument IntelligenceにOCRをしてもらった結果をうけとっています。
このとき返却されるのが、AnalyzeResultクラス。
このクラスでモデル作成に使用したのは、Documents。(1レコードしかない)
こちらに請求書モデルとして抽出した値が格納されています。
(ここのContentには読み取れた文字がずらっと連結されて並んでいるだけ)
もし明細があり、テーブル形式で情報を取得したい(ただし信頼度は取得できない)場合は、Tablesで取得が可能です。
Documentsを使用した場合
AnalyzedDocumentクラスになります。
Fieldsで取得できるのが、👇のDocument Inteligence StudioでOCRをしたときに結果が表示される部分のここです。

Itemsは明細の内容が入っているのですが、ここの値を取得したい場合は、以下のようなひと手間が必要になってくるようです。
private List<TableItemsData> FormatAnalysisOfTableItems(DocumentField documentField) { var listValue = documentField.Value.AsList(); var tableItems = new List<TableItemsData>(); for (int i = 0; i < listValue.Count; i++) { var fieldItems = new List<Models.FieldData>(); var tableItem = new TableItemsData(); if (listValue[i] != null) { var dictionaryValue = listValue[i].Value.AsDictionary(); if (dictionaryValue != null) { foreach (var dictionaryEntry in dictionaryValue) { var valueEntry = new Models.FieldData(); valueEntry.Key = dictionaryEntry.Key; valueEntry.Content = FormatAnalysisOfContent(dictionaryEntry.Value); valueEntry.Confidence = dictionaryEntry.Value.Confidence; fieldItems.Add(valueEntry); } tableItem.Items = fieldItems; tableItem.No = i + 1; } } tableItems.Add(tableItem); } return tableItems; }
Tablesを使用した場合
DocumentTableクラスになります。
ひとつひとつのTableを解析したい場合は、以下のコードをかいてみます。
送ったファイルはMSのサンプルファイル。
var table = analyzeResult.Tables[i];
すると、DocumentTableCellクラスとなります。
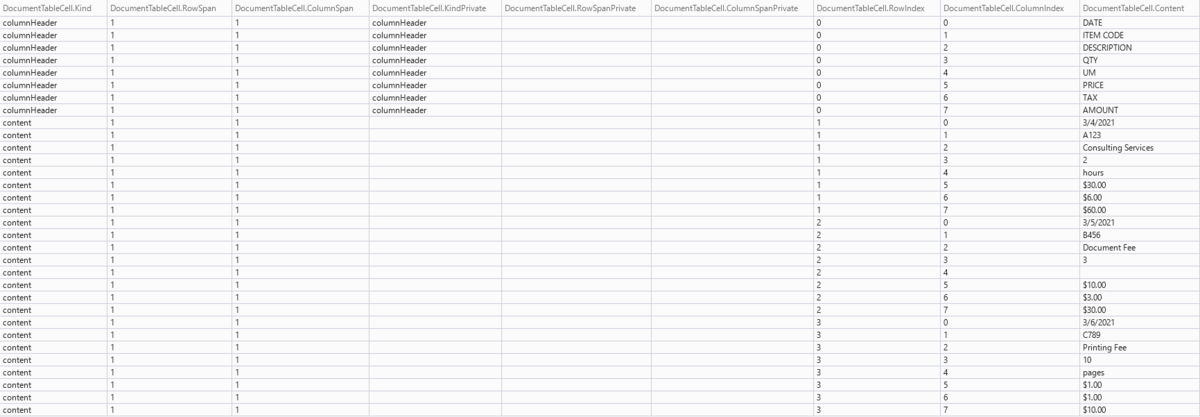
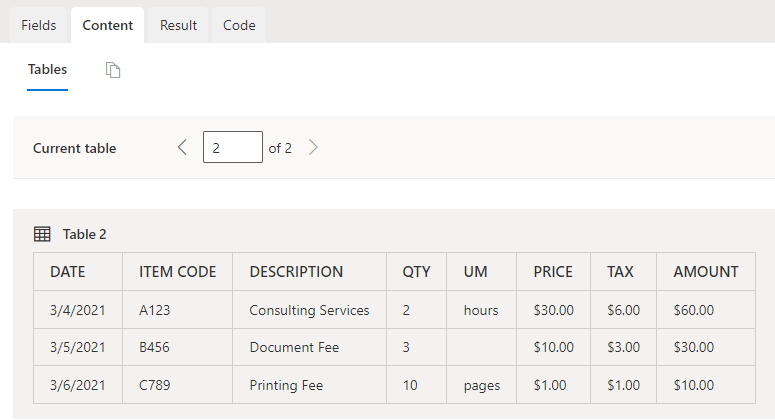
この値を駆使することで、👇のDocument Inteligence StudioでOCRをしたときに結果が表示される部分のここのTableが作成可能です。
感想
いろいろとDocument Intelligenceをさわってみましたが、精度はかなり高く、素晴らしかったです。ただ、項目がいっぱいあると加工するのが大変だなと思いました。