はじめに
Document Intelligenceのカスタムモデルの調査と実際に試してみたため、その内容をまとめています。
カスタムモデルとは
Document Intelligenceには請求書や領収書など、すでに学習されたモデルが存在します。
ですが、このモデルには存在しない項目も読み取ってほしい…などの要望がある場合、自分でカスタマイズしてモデルを作成することができます。
また、100個までのカスタムモデルを1つのモデルIDに割り当てることが可能です。
(このドキュメント(カスタムモデルを作成する)を見ると上では200個とかいていますが、下では100個とかいてあり、どちらが正しいか不明…)
学習データに関して
最低学習データ必要枚数は5枚です。
ただ、もちろん学習データが多ければ多いほど精度は上がります。
価格
従量課金の場合
1000ページあたり約7.316円 ⇒ 1ページあたり約7.3円となります。
学習済みモデルでは1ページあたり約1.5円だったため、約5倍高くなります。
価格 - Form Recognizer API | Microsoft Azure
2通りのモデルの作り方
カスタムモデルを作成するにあたり、2つの作成方法が可能だと感じました。
私の場合、様々な書式の請求書があるため、書式ごとにカスタムモデルを作成し、最後に統合する方法が合っていたと感じました。
同じ書式のデータを5枚以上集め、カスタムモデルを作成し、最後に統合する
イメージ図👇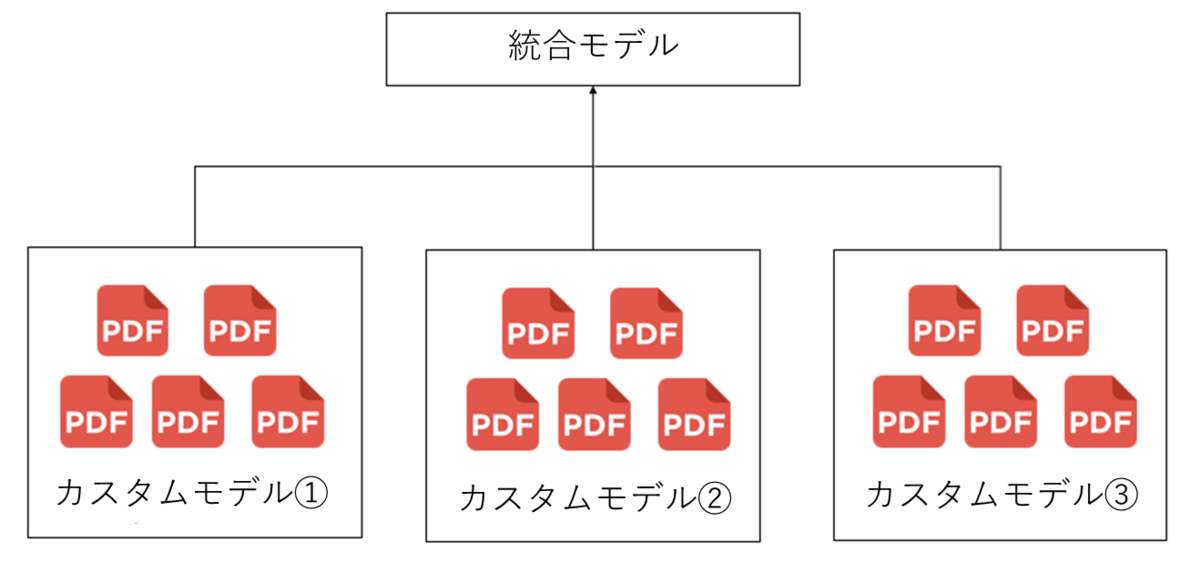
この方法でテストをしてみると、テストをしたファイルはどのモデルに当てはまるかが分類され、最も適するモデルを使って結果を返してくれます。
(統合モデルは作成済みモデルというらしい)すべての学習データをひとつのカスタムモデルで学習
イメージ図👇

カスタムモデル作成方法
リソース作成方法は割愛します。
Document Intelligence Studioを使った方法を記載してます。
Custom extraction modelを選択します
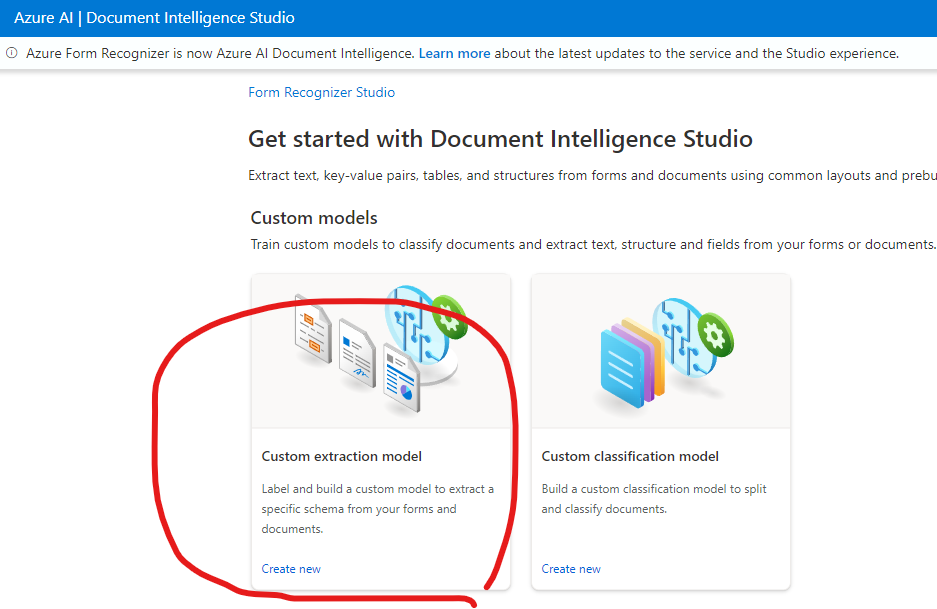
Create a projectからプロジェクトを作成します
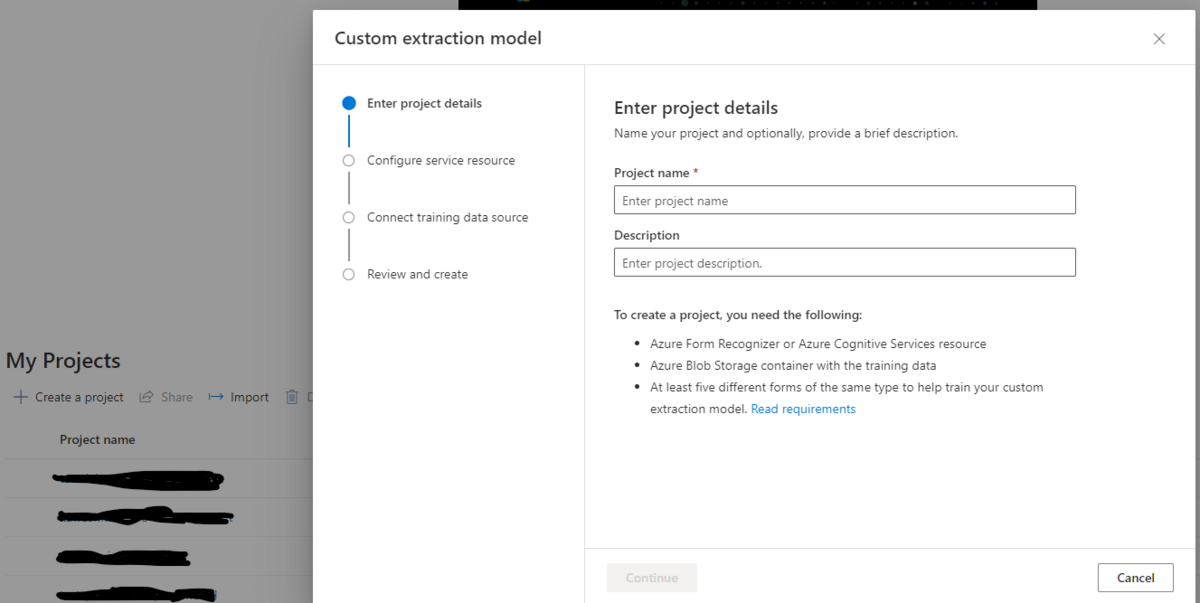
入力するのはプロジェクト名とその説明Document Intelligenceリソースの設定をすることで紐づけます
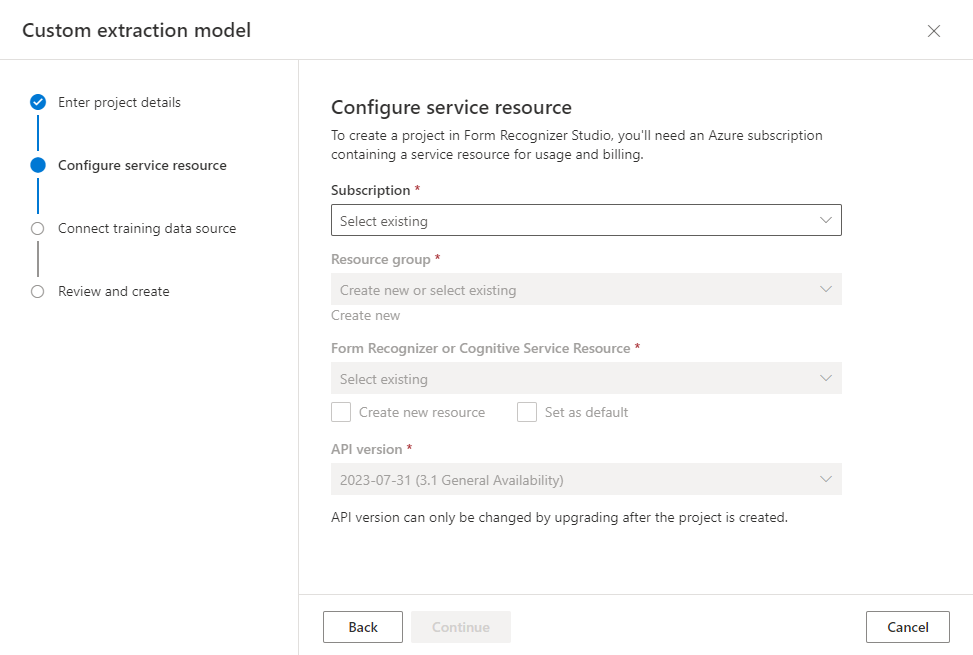
学習データを保存するストレージの設定をすることで紐づけます
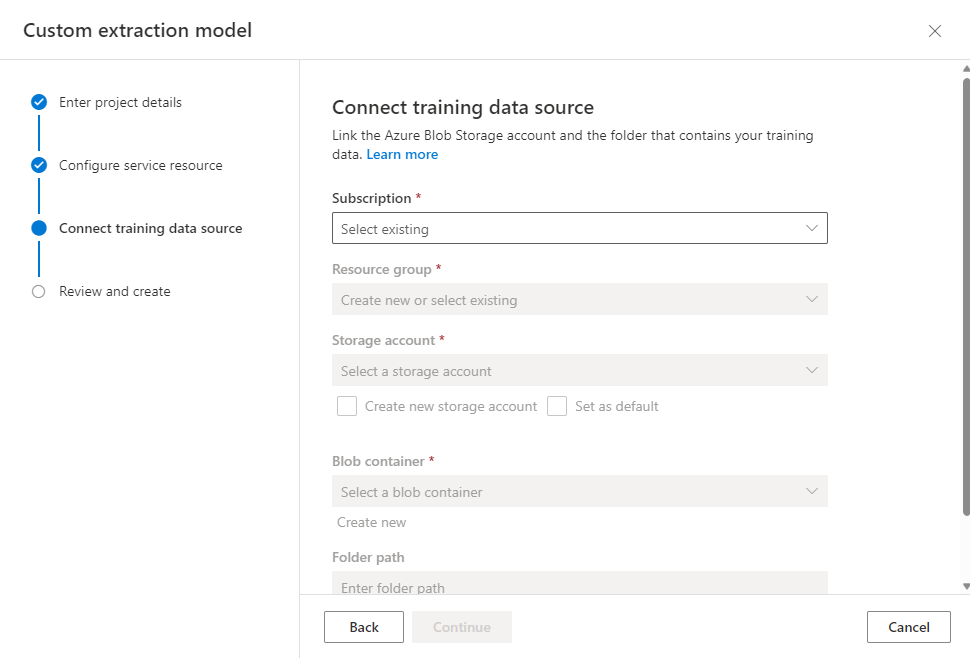
以上でプロジェクトを作成する上での設定は終了です。続いてラベルをつける作業になります
Auto labelでここのModel Idを例えばinvoiceにすると、ある程度請求書モデルに合った形でラベルをつけてくれます。
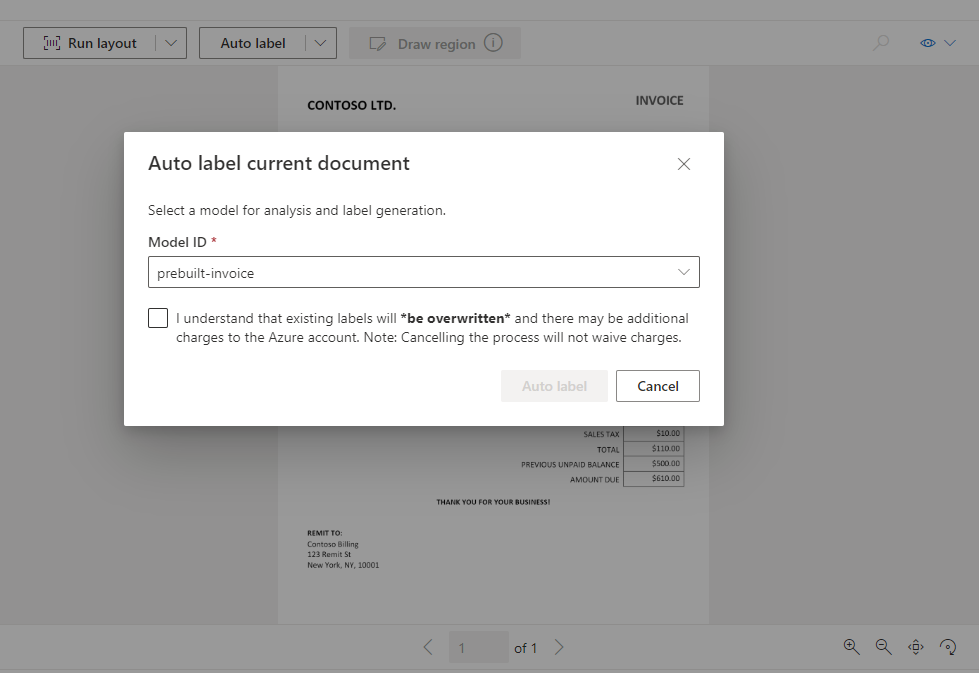
上記ラベル作業で足りなかった項目があった場合、Draw regionを選択することで、自分で読み取ってほしい部分を選択してラベル付けすることができます
最後にTrainをすることでカスタムモデルが完成します
モデル作成に少々時間がかかるので息抜きタイム☕
カスタムモデルを試した所感
5枚でもそこそこの精度を出すことができるが、学習データがもう少しあれば精度はもっとあがりそう(特に手書き)
意外とどちらのモデルの作り方でも大きく精度が異なることはない(項目が増えるので、モデルを分けた方がいい気もするけど…)
ラベルを作る作業が地味に大変
一度作成したカスタムモデルを再トレーニングする方法が見つからなかった (一度作成したモデルを削除してもう一度トレーニングする方法しかない?)